Trie 树
有一个记录了数个网站 Web 请求的日志文件,字段分别为客户端 IP、请求方法、子域名,URI,如下:
192.168.56.1 GET www.a.com /index.jsp 192.168.56.2 GET www.b.com /index.asp ...
还有一个记录了一级域名的文件,如下:
a.com b.com c.com ...
现在,需要以一级域名为单位,把它所有子域的日志提取出来。
简单的方法就是将域名转为“列表”结构载入内存,逐行遍历日志,提出域名字段,再遍历域名列表做判断:
def find(host): """ @Args host: 日志行中的主机地址 @Return:如果域名在列表中,返回 True """ for domain in domain_list: if host.endswith(domain): return True return False
每行日志都去遍历一次列表,效率很低,尤其是列表非常大的时候。
现在用 Trie 树来优化,把一级域名按“.”分割后,以倒序创建一棵树结构,比如 a.com、b.com 和 c.org 的树结构如下:
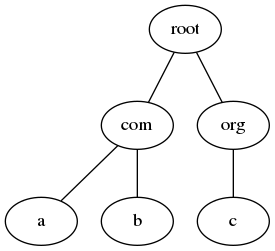
遍历日志时,对域名字段用同样的方式分割,再倒序搜索树即可。实现如下:
tree = dict() def insert_tree(item_list): root = tree for i in item_list: if not root.get(i): root[i] = {} root = root[i] def search_tree(item_list): root = tree for i in item_list: # 这里不能直接写成 if root.get(i) # 因为if判断空字典为 False if root.get(i) is None: return False # 到叶节点了,说明找到记录 if root[i] == {}: return True root = root[i] return False def insert_domain_to_tree(domain): domain_items = domain.split(".") domain_items.reverse() insert_tree(domain_items) return def search_domain(domain): domain_items = domain.split(".") domain_items.reverse() return search_tree(domain_items) def init_tree(): with open("domain_list.txt") as f: for line in f: domain = line.strip() insert_domain_to_tree(domain) if __name__ == '__main__': # self test init_tree() assert(search_domain("www.a.com") is True) assert(search_domain("test.b.com") is True) assert(search_domain("test.xx.com") is False)